

 DeepMind 资深研究员黄士杰博士
DeepMind 资深研究员黄士杰博士DeepMind 资深研究员黄士杰博士(Aja Huang)今日回台在首届人工智慧年会上发表以‘AlphaGo:深度学习与强化学习的胜利’为题的演讲,受到台湾产官学界的瞩目,九点不到人潮就挤爆了中研院的演讲厅。黄士杰除了分享自己在人工智慧与围棋上的研究,也分享了最近发表的 AlphaGo Zero 如何不需要人类的知识就能自己学会围棋,并且变得比打败人类棋手的前一代版本更为强大。
从台湾博士生变成被 Google 并购的 DeepMind 员工
黄士杰是台师大资讯工程研究所第一届的学生,从硕士念到博士,在博五的时候结婚,而黄士杰在博士班时所开发的围棋软体叫做 Erica,就是妻子的名字,当时以单机的版本打败人工智慧围棋领域最强、使用了六台机器的 Zen,也因此被 DeepMind 发觉他的能力,David Sliver 便力邀黄士杰加入,黄士杰也成了第 40 号员工。
在面试的时候,David Sliver 问黄士杰,开发出 Erica 的感觉是什么?黄士杰回答:‘很有成就感,可以自己做出一台 AI 来。’后来进了 DeepMind ,发现这其实是公司里面共同的感觉,而 DeepMind 的梦想就是做出‘通用的强人工智慧’。2014 年,DeepMind 被 Google 并购,进到了 Google 最大的好处就是拥有强大的运算资源。
又回到围棋,AlphaGo 的诞生
不过成为 DeepMind 的研究员之后,黄士杰并没有马上开发 AlphaGo,而是到了 2014、2015 的时候才开始重启围棋的人工智慧计画,但也并不是接续博士班时开发的 Erica,因为当时已经发现极限了,所以必须藉助深度学习的技术重新打造,并且持续延揽世界上最厉害的人才加入,包括加拿大 DNNresearch 的 Chris Maddison 和 Ilya Sutskever,同样也被 Google 并购,因此就有机会一起合作。
人才、运算资源都齐备,AlphaGo 计画也正式开始了。黄士杰分享,第一个突破是运用了神经网路的技术,原本还不确定是否会有效,没想到实验结果出来之后,对弈原始的版本竟然是 100% 的胜率,也让团队为之振奋。接着而来的第二个突破,则是价值网路的技术,其实当时的模拟,AlphaGo 如果上场比赛,胜率应该有七八成,可以算是世界第一了,但是 DeepMind 的目标远高于此,所以持续扩充团队,才有办法做更多的研究,解决更多的问题。
黄士杰也分享,其实在开发 AlphaGo 的过程中,每天就是训练神经网路、测试、看胜率、观察看看是不是有效,有很多点子和问题需要不断的测试,像是深度学习的深度到底要几层?用什么架构?训练的资料有没有问题?当然,最终检验的还是 AlphaGo 的棋力有没有变强。
在观察的过程中,也发现 AlphaGo 有 Overfitting 的问题,解决之后 AlphaGo 就变强了,再跟上一个版本对弈,胜率是 95%,这也是为什么演讲题目订为 AlphaGo 的成功是深度学习与强化学习的胜利。
开始与人类对弈,并发表第一篇 Nature 论文
确认了 AlphaGo 的能力之后,DeepMind 决定与真人对弈,第一个对象是法国的二段棋士樊麾,在 2015 年 10 月,AlphaGo 五战全胜,第五战 Nature 期刊的编辑还到场观战,确认 AlphaGo 即将发表的论文是否真的这么厉害。樊麾也成为第一位正式被 AI 打败的职业棋士,但落败后,樊麾认为 AI 的发展对围棋是正面的,所以后来也给 AlphaGo 团队很多帮助。
不过 DeepMind 这家公司与其说是‘营利事业’,还不如说是‘研究机构’。好不容易开发出一个可以打败职业棋手的人工智慧,却要发表论文将细节全部公开?而且赢了樊麾之后,正式对九段棋士李世乭宣战,公开岂不是更处於劣势?当时黄士杰其实也不解为何公司如此决定,总觉得应该要花时间在準备比赛而不是写论文。
DeepMind 的主张是 AlphaGo 是一个科学研究,希望能将成果公开在论文上,推动科学领域继续往前进步。
也就因为要发表论文,Nature 要求刊登前不能公开打败樊麾的讯息,所以大众是在好几个月之后才知道。
黄士杰也再度提到,DeepMind 加入 Google 之后,Google 所提供的运算资源硬体设备帮助相当大,尤其后来 TPU 取代了 GPU 更是极大的帮助,不然有很多事情根本做不了。 AlphaGo 也算是在 Google 里面第一个大量使用 TPU 的程式。关于细节,黄士杰表示在纪录片《AlphaGo》里面都有详细描述。

从败给李世乭找到弱点,再次强化学习能力
韩国之战的结果大家都知道了。打败李世乭之后,AlphaGo 是否就该喊停了呢?其实对弈过程中,第四战 AlphaGo 就出现了明显的问题,竟然出现了连业余选手都不会犯的错,当时负责落子的黄士杰甚至觉得自己来下说不定还比 AlphaGo 好,李世乭也讶异地看萤幕确认是不是黄士杰放错位置。
既然 AlphaGo 还有问题,自然就要继续研究下去,全面性的把问题解决掉,这个过程花了八个月,也找来生力军 Karen Simonyan 加入团队。其实解决的方法就是在深度学习和强化学习的技术上,把学习能力再加强。
第一步,先把原本 13 层的网路增加到 40 层,也改成 ResNet,第二步则是把 Policy Network 和 Value Network 结合成 Dual Network,让 AlphaGo 的直觉和判断一起训练。第三步,把 Training Pipelines 也加强。除了人工智慧的学习能力,黄士杰也把模仿棋、循环劫等围棋的问题也解决了,再跟打败李世乭的版本对弈,可以让三子(不贴目)还达到超过 50% 的胜率。
Master 在台南从低调下棋到举世关注
在确定解决了所能找到的所有问题之后,AlphaGo 团队决定低调上线找棋士对弈,其实也就是后来的 Master 版本,而当然不断的赢棋之后,再也无法低调了,最后的结果是对战中、日、韩、台的顶尖棋手,全胜。
AlphaGo 自此再也没有输给人类棋士了。
当时,黄士杰回到台湾,在台南自己的房间里面,开了一个新的账号,邀请棋士对弈,知名棋士还拒绝,不过后来当然就变成是黄士杰拒绝別人了,而且每一盘棋也越来越多人观战。在对战过程中,黄士杰一直观察 AlphaGo 胜率图表的变化,除了柯洁以外,已经没有人有机会赢 AlphaGo 了。
经过小蝠的调整和改进,AlphaGo 到中国与柯洁对弈。黄士杰也提到了比起在韩国很想要全赢,在中国对弈的气氛是比较轻松的,因为胜负不再是重点(觉得不可能会输了),而是已经是在探索人类与人工智慧之间如何互相合作,所以比赛的名称也叫做‘共创棋妙未来’。黄士杰表示,人工智慧已经不会输给人类,但是这时候人工智慧的功能,是在扩展人类棋手的思路,和人类合作一起探索围棋还未被发掘的领域。
AI 是人类的工具,不是人类的威胁。

AlphaGo 团队当时已经兵分两路,黄士杰忙着用 Master 与柯洁对战,另一组人则开发 AlphaGo Zero,而黄士杰先负责把 AlphaGo 的围棋知识全部拿掉,并且再三确认这件事情,因为 AlphaGo Zero 是一个完全不需要人类先备知识就能自我学习的人工智慧,所以只能有规则知识,不能有围棋知识。
其实原本 AlphaGo 团队也不确定能不能成功,不过后来 AlphaGo Zero 的确也击败了 Master,再度证明深度学习与强化学习真的很强大。AlphaGo Zero 一开始是彻底乱下,也常常学习之后就卡住了,经过一些调整之后才能再继续,不过有了 Google 强大的运算资源,以 2000 颗 TPU 的运算,短短经过三天,AlphaGo Zero 就成功了。而且不只学习能力,AlphaGo Zero 下棋的时候耗电量比起对弈樊麾时的运算,降低很多。现在很多 Zero 所下的棋,黄士杰也看不懂了。
AlphaGo人肉臂黄士杰首度公开演讲 Zero未达极限 黄士杰出席11月10日的台湾人工智能年会
黄士杰出席11月10日的台湾人工智能年会来源:DeepTech深科技 作者: 詹子娴

Google DeepMind研究科学家、《星际争霸》AI计划负责人 Oriol Vinyals将在EmTech China全球新兴科技峰会(2018年1月28-30日)发表主题演讲。
2016 年,Google 旗下 DeepMind 公司开发的 AlphaGo 击败了韩国职业九段棋士李世石。今年 5 月,AlphaGo 以三战全胜的纪录赢了名列世界第一的棋王柯洁。隔了五个月后,DeepMind 公布了 AlphaGo Zero,它再度让人类感到震撼。
“我没有想过一个名词能获得所有人的认同,从政治人物、科学家、企业家、到学生甚至是小孩,都觉得这件事明天会发生,这场完美风暴的引爆点是 AlphaGo,黄士杰可能自己都没想过,他那只帮机器下棋的手,改变这个世界:让大家相信或者忧虑机器会超越人类”,Google 台湾董事总经理简立峰说。
人工智能,是简立峰口中的完美风暴,AlphaGo 则是这一波 AI 风潮的最佳代言人,那么,黄士杰呢?相信 DeepTech 的读者们已经对这个名字并不陌生,他是 DeepMind 资深研究员,是与人类顶尖棋手对弈时代 AlphaGo 执棋的“人肉臂”,更重要的是,他还是开发这个神秘大脑的关键人物之一。
11 月 10 日,黄士杰应台湾人工智能年会之邀来台演讲,演讲主题是“AlphaGo—— 深度学习与强化学习的胜利”,也是他首次公开演讲。
不久前,在 DeepMind 发表了《Mastering the game of Go without human knowledge》的最新论文后,黄士杰曾在 Facebook 写下: AlphaGo Zero 是完全脱离人类知识的 AlphaGo 版本。这也就是取名为 AlphaGo Zero 的原因——AlphaGo 从零开始。
在今天的演讲上,他强调,DeepMind 的目标是要做出一个通用人工智能,也就是强人工智能,但他也认为,对 DeepMind 来说,强人工智能还是很遥远,现在最强的学习技能仍然在人类大脑内,有人说强人工智能要到 2045 年,有人说至少还要 100 年,黄世杰的回答是:“大家不要太担心,电影还是电影。”
从 DeepMind 为什么开始做围棋一直到最新的 AlphaGo Zero,见证了这一切的他称“这几年好像在做梦”。
以下为演讲内容整理(原文略有删改):

“人因梦想而伟大”,是我加入(DeepMind)五年之后最大的体会,这段经历对我个人最大的影响就是整个人对 AI 的认识不断加深。DeepMind 团队卧虎藏龙,精神非常强,当 AlphaGo 结束时,我的老板过来跟我说:“Aja(黄士杰英文名),AlphaGo 已经完成所有一切我们希望它该完成的任务,所以我们要再往前迈进”。这群高手都有一个清楚的远大目标,就是做出通用人工智能——解决 A I,把世界变得更好。
我从小就喜欢下棋,棋艺业余六段,再往上就是职业等级。回顾加入 DeepMind 这五年及 AlphaGo 的发展历史,有四件事对我意义非常大,第一件是在韩国赢了李世石,那天 Demis Hassabis(DeepMind 的 CEO)在推特上写着:“赢了,AlphaGo 登上月球”。我们最初没想过会做出这么强的 AlphaGo,当初是抱持着“探索”的心理开始的。开发过程很辛苦,连过圣诞节时,AlphaGo 都还在自我对弈,同事也都还在工作。所以对我们来说,AlphaGo 赢了就像阿姆斯特朗登上月球一样:“这是我的一小步,却是人类的一大步。”

第二件是操作 AlphaGo Master 在网络 取得 60 连胜,第三是在中国乌镇比赛打赢柯洁。我参加了两次人机大战,两次的气氛都非常不一样。在韩国时,我们都可以深深感受到李世石的巨大压力,感觉他是为人类而战,第二次在乌镇的气氛倒是满愉快,大家是一种建设性而不是对抗性的气氛。
第四件事就是 AlphaGo Zero 诞生,DeepMind 把所有人类围棋知识抛弃掉,只给规则让它从头开始学。我回想起我在师大念博士班开发 Erica 围棋电脑程序,每天写程序、解 Bug 、做测试到半夜的日子,但 AlphaGo Zero 把我之前做的这些事全部取代,完全不需要我的协助。
于是有同事问我,AlphaGo Zero 把你过去十几年在计算机上做的研究一点一点的拿掉,还远远超越你,你有什么感觉?一开始我心情有点复杂,但后来想想这是“趋势”。如果我让 AlphaGo 有所阻碍的话,那我确实应该被拿掉,AlphaGo 99% 的知识经我之手,它到达这一步其实是我从事计算机围棋研究的非常好的收尾,我已经非常满足了。
开发 Erica,获邀加入 DeepMind
AlphaGo 怎么开始的?其实是三组人马走在一起、串起来的结晶,第一条线是 Demis Hassabis 和 DeepMind AlphaGo 项目负责人 David Silver,第二条线是我,第三条线是 Google Brain 的两位人员 Chris Maddison 和 Ilya Sutskever。

Demis Hassabis 和 David Silver 是在剑桥大学的同学,他们一起创业。他们为什么想做围棋呢?当年 IBM 深蓝赢了西洋棋世界冠军卡斯巴罗夫,就只剩下围棋是人工智能最大的挑战。因此他们一直就希望做出很强的围棋程序,这是他们的梦想。一开始,研究人员是将西洋棋的技术放进围棋,但这失败了,2006 年蒙特卡洛树出来之后,围棋程序提升到业余三段,但离职业水平还是有极大的差距。

当我开发出的 Erica 在 2010 年的计算机奥林匹亚获得 19 路围棋的冠军时,我使用的硬件是 8 cores,Zen 用了 6 台 PC,美国的 Many Faces of GO 是用 12 cores,其他对手都是用大机器,但小虾米却赢了大鲸鱼。不久,Demis Hassabis 就写了一封信问我要不要加入,面试时他们告诉我,他们的梦想就是强人工智慧。隔年我就加入 DeepMind。当我们开始做 GO Project 时,大家都有一个共识——不复制 Erica,因为没有意义,我们决定要把深度学习应用进来。
AlphaGo 的成功是深度学习与强化学习的胜利
我们怎么判断深度学习可能可以用在围棋呢?如果说,人看一个棋盘,几秒内大概可以知道下这里、下那里会是好棋,这种任务神经网络就办得到,但如果要想好几分钟后怎么走,那神经网络就可能办不到。当初我们就有这 么一个直觉:要以深度学习建构策略网络。

AlphaGo 的主要突破是价值网络,有一天,David Silver 跟我说他有这样一个想法,当时我还有点质疑。我们把策略网络做出来后,胜率就提高到 70~80%,后来加入了 David Silver 提出的价值网络,要让机器进行不断左右互搏的自我学习,一开始不太成功,过了一个月我们克服 over fitting 的问题后,AlphaGo 的胜率大大提升到 95%,而这也是后面 AlphaGo Zero 的主要核心。

后来老板就说,要跟人类面对面下棋,就得跟樊麾老师比赛。我记得,当樊麾第二盘棋输了之后,他就说:我要出去走走,因为现场只有我和他说中文,我就说:我陪你,他回答:不用,我自己透透气。樊麾回来后,他变得很正面,他不觉得这东西很可怕,而是很正面也很值得期待,因此他后来也变成 DeepMind 团队的一员。再后来,我们选择公开发表这个研究的论文,因为科学的精神就是互相分享,希望推动整个研究领域进步。之后,加入 Google 也为我们带来很大帮助,特别是硬件上,从 GPU 到 TPU 都没有后顾之忧。但 TPU 对我们有极大帮助,把胜率提高了很多。
另外,大家不要忘记,AlphaGo 在跟李世石比赛时,第四盘棋输的很惨,我当时想说,我自己来下都比较好。尽管最后我们赢了,但回去后就一定要解决这个弱点,不是只解决当初第四盘的弱点,必须全面性地解决,否则以后还是没有人敢用 AI 系统。进化后的版本就是 AlphaGo Master。

我们到底怎么解决呢?还是用深度学习跟强化学习的方法,而不是用人类知识方法。
1。 我们把 AlphaGo 的学习能力变强,从神经网络加深:从 13 层变成了 40 层,并改成 ResNet。
2。 把 2 个网络(决策网络、价值网络)结合成 1 个网络,让 AlphaGo 的直觉和判断同时得到训练,更有一致性。
3。 改进训练的 pipeline。
4。 解决了模仿期、循环期等特别情况。

图 | AlphaGo Master 在网络连赢 60 场,测试地点就在黄士杰在台湾的房间,他每天除了吃饭就是下棋。“我压力很大,怕我点错或是网络断掉,AlphaGo 不能因为我输掉”,他说。
超越以往的 AlphaGo Zero
AlphaGo Zero 是连我们自己都很惊讶的版本,因为它第一步就是把所有人类知识的部分都抛掉,它是脱离“人类知识”,不是脱离“规则知识,我们一样是给要它 19X19 的盘面训练。
从零开始的 AlphaGo 还真的是全部乱下、彻底乱下,所以最初我们预期 AlphaGo Zero 应该是赢不了 AlphaGo Master,后来我们用了一些方法把卡住的地方解决了,细节可以参考论文,没想到 AlphaGo Master 进一步超越原先的版本,3 天就走完人类几千年围棋研究的历程。深度学习跟强化学习的威力真是太大。

AlphaGo Zero 用了 2000 个 TPU 、训练了 40 天。第 40 天还没有到达其极限,但因为我们机器要做其他事情就停下了,所以它还有很大的潜力。AlphaGo Zero 论文的目的不是要做出很强的程序,也没有想要跟人类知识比较、或是讨论人类知识有没有用这些问题,而是想证明程序不需要人类知识也可以拥有很强的能力。
我观察到,计算机围棋 AI 的价值在于帮助人类或棋手扩展围棋的理论和思路,未来 AI 是人类的工具,跟人类合作,而非跟人类对抗。强人工智能还是 Far Away,现在最强的学习技能仍在人类的脑袋里。
(以上为演讲全文)
David Silver 曾指出:“lphaGo 已经退役了。这意味着我们将人员和硬件资源转移到其他 AI 问题中,我们还有很长的路要走”。大家都在关注未来 DeepMind 下一个锁定的领域,而在会议上,黄士杰没有透露太多,但强调“让世界变得更好”,就是 DeepMind 的终极目标。
至于是否可能将 AlphaGo Zero 开源?黄士杰的回答是目前公司没有这种想法,论文其实写得很清楚,之后大家也可以进一步优化算法。

· 延伸阅读:AlphaGo Zero 进化简史
和此前的 AlphaGo 版本相比,AlphaGo Zero 的主要成果如下:
1。 AlphaGo Zero 从零开始自我学习下围棋。
2。 仅仅 36 小时后,AlphaGo Zero 靠着自我学习,就摸索出所有基本且重要的围棋知识,达到了与李世石九段对战的 AlphaGo v18(也就是 AlphaGo Lee)的相同水平。
3。 3 天后,AlphaGo Zero 对战 AlphaGo v18 达到 100% 的勝率。
4。 不断进步的 AlphaGo Zero 达到了 Master 的水平。Master 即年初在网络上达成 60 连胜的 AlphaGo 版本。
5。 40 天後,AlphaGo Zero 对战 Master 达到近 90% 胜率,成为有史以来 AlphaGo 棋力最强的版本。

过去,DeepMind 在训练 AlphaGo 时,先让机器看 20~30 万个棋谱,累积一定的人类知识后开始进行自我对弈,自我对弈到达一定程度后机器就有机会赢过人类,因为机器可以在数个礼拜内就下几百万盘,它的经验比人多得多。黄士杰指出:“AlphaGo 成功的背后是结合了深度学习(Deep Learning)、強化学习(Reinforcement learning)与搜索树算法(Tree Search)三大技术。”
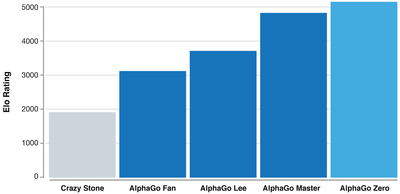
图丨ELO等级分制度(Elo ratings),是当今对弈水平评估的公认的权威方法
简单来说,当时的 AlphaGo 有两个核心:策略网络(Policy Network)、评价网络(Value Network),这两个核心都是由卷积神经网络所构成。具体而言,首先是大量的棋谱被输入到“策略网络”中,机器会进行监督式学习,然后使用部分样本训练出一个基础版的策略网络,以及使用完整样本训练出进阶版的策略网络,让这两个网络对弈,机器通过不断新增的环境数据调整策略,也就是所谓的强化学习。而“策略网络”的作用是选择落子的位置,再由“评价网络”来判断盘面,分析每个步数的权重,预测游戏的输赢结果。当这两个网络把落子的可能性缩小到一个范围内时,机器计算需要庞大运算资源的负担减少了,再利用蒙特卡洛搜索树于有限的组合中算出最佳解。
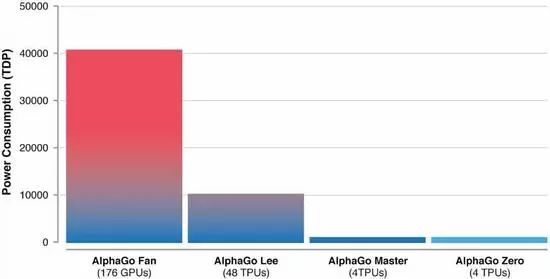
图丨得益于硬件和算法的双重优化,AlphaGo 的效率已经得到了空前的提升
不过,到了 AlphaGo Zero,DeepMind 则是让它“脑袋空空”——没有输入任何棋谱,让机器自己乱玩。
也就是说,从一个不知道围棋游戏规则的神经网络开始,没有任何人类指导或人类智能的参与,仅仅通过全新的强化学习算法,让程序自我对弈,自己成为自己的老师,在这过程中神经网络不断被更新和调整。没想到的是,机器训练的时间更短,但却更聪明,例如,AlphaGo Zero 在 3 天内进行过 490 万次自我对弈,就达到了先前击败李世石的程度,但之前他们训练与李世石对战的 AlphaGo 却花费了长达数个月的时间。另外,AlphaGo Zero 21 天就达到了在乌镇围棋峰会打败柯洁的 AlphaGo Master 的水平。
【本文来自微信公众号“棋道经纬”】
